Paper reading - Fit and Prune Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models
任务
当前MLLM依赖于大量的视觉token做出高精度的视觉推理,例如LLaVa使用576 image patches as visual tokens,这相较于纯文本带来了6.2倍的计算时长开销。此外,一些其他工作正在使用提高图像分辨率的方法来缓解MLLM的视觉缺陷,但进一步加剧了计算量。
作者想要得到一种方法来在MLLM的图像token输入中,进行压缩,从而进行推理时的加速,且不能太影响下游任务精度。
同时,作者认为先前的方法依赖于大量的实验来确定超参数,他提出的方法需要具有一定的泛化能力,并且超参数确认简单 can be obtained in about 5 minutes for all VL tasks
motivation
- 大规模视觉token在MLLM中的存在明显的冗余,MLLMs 的多头注意力机制是单向的,而非真正“全局”的。简而言之,MLLMs 仅将信息从前一个标记传递到后一个标记,其视觉标记通常置于文本问题之前。在这种情况下,它们主要作用是为文本标记提供视觉语义,但实际上其中大部分并未被激活。
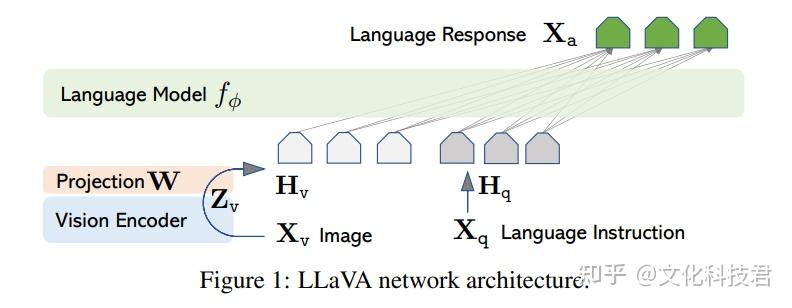
如图,大部分蓝色部分(不相关语义)实际上几乎不参加推理,�图像到文本注意力非常集中。
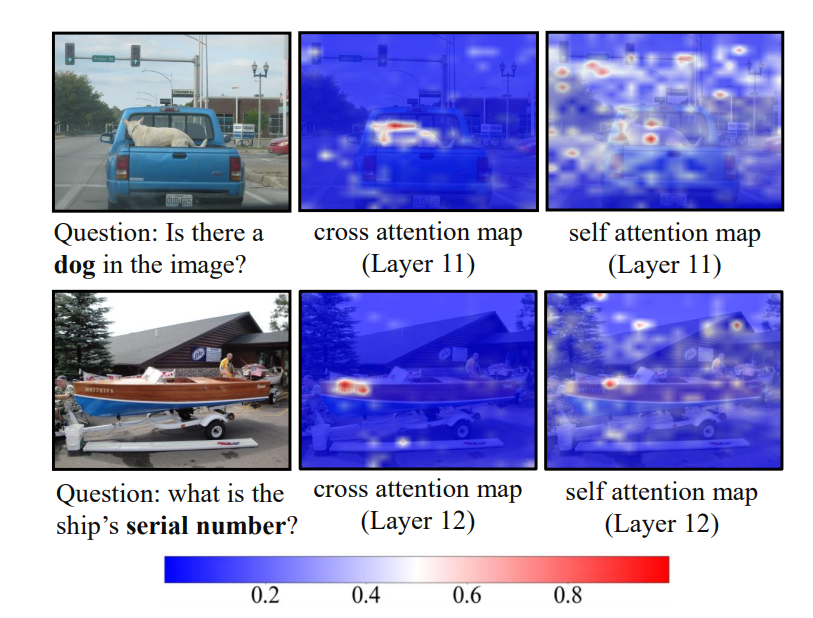
- 作者将确定压缩比例这一超参数的问题转换成一个统计问题。将压缩问题转换为这样的问题:给定一个采样样本集合, 再给定一个计算开销 ,设压缩策略为, 目标是找到一个压缩比够大(满足计算开销到以下)的,使得在上整体的注意力分布变化最小
方法
作者只对多头注意力层进行修剪
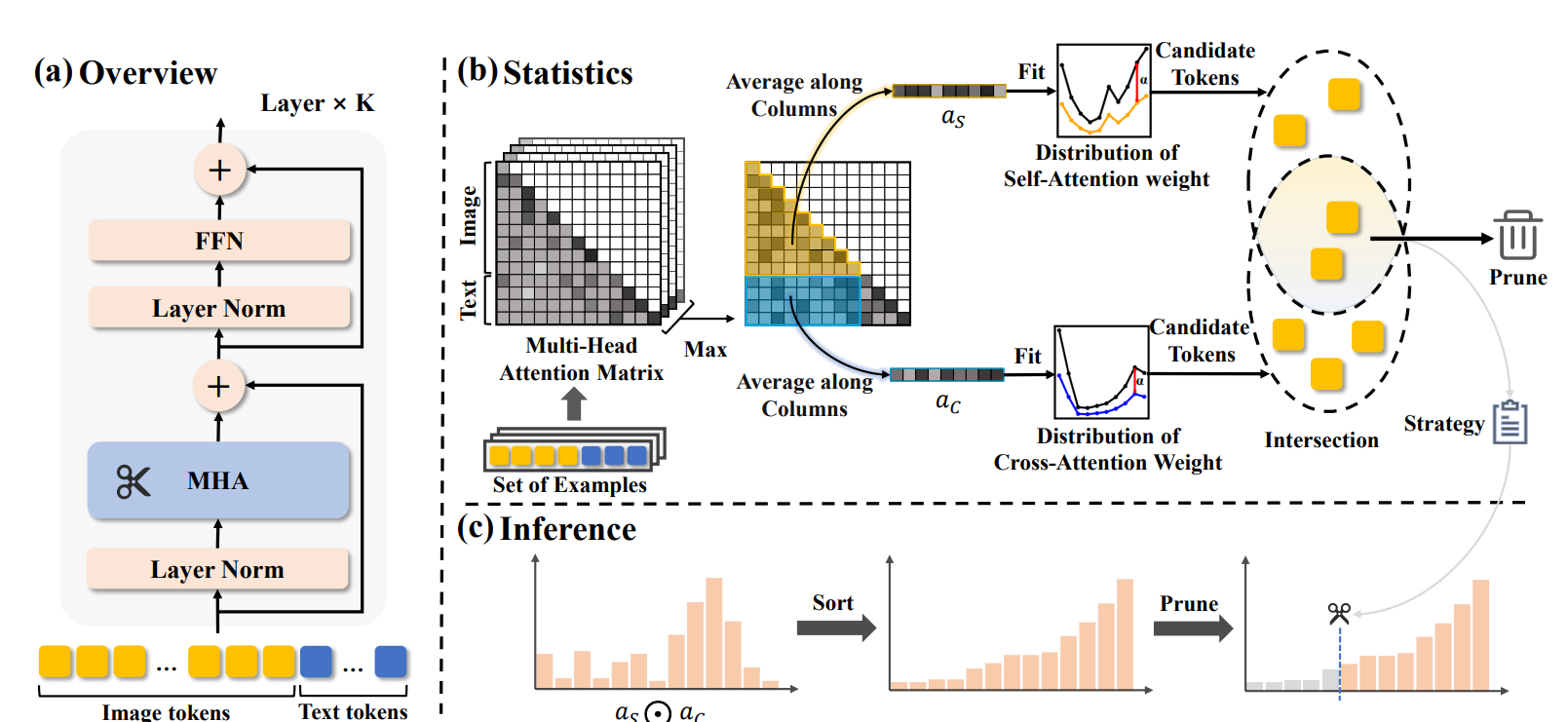
得到修剪策略
对于采样样本集, 计算每一层的视觉token自注意力和视觉-文本交叉注意力。假设视觉token数N,文本token数M,第i层的第j个视觉token的平均注意力为 , s和c分别代表自注意和交叉注意,A代表是在上取的平均
移除策略P可以建模成 (假设模型有k层)
表示在第i层新移除的token数量,注意前面层移除的token也不会传递给后面层,也就是说移除的总数是单调增的
采用一个注意力相差阈值和计算开销两者一起控制裁剪,具体来说,是提前给定的,是二分查找计算出来的值

用通俗的话翻译就是:
- 将注意力分布的差别简化为平均每个token的自注意力/交叉注意力之和的差别,即是否删除某个token,注意力和的相对变化需要小于阈值
- 由于只计算和,所以可以对自注意力、交叉注意力两个集合分别按照大小排序 —— 注意力分布变化最小的保证转化为,总是优先考虑删除注意力最小的token
- 给定一个阈值, 对于每一层遍历,对于自注意力、交叉注意力分别不断尝试删除token,直到注意力变化达到阈值, 而这一层最后的策略P,即token删除数量为自注意力删除集合和交叉注意力集合的交集的大小
- 现在有了一个删除策略, 计算它是否满足计算开销约束(文中并没有具体说是怎么计算的,应该是根据模型的删除后token和参数量估算FLOPS,或者是某种直接测量计算量的工具,�用的显卡是单张A100)
-
如果满足,说明删除策略是可行的,但说不定太大删除太多了,需要调小;如果不满足,说明删除策略不可行,说明太小了,需要调大。因此,二分查找直到找到一个满足计算开销约束的,且这个的左右区间长度小于阈值(后文实验是0.01),则这个对应的删除策略就是最终的删除策略。
-
最后效果是在满足计算开销约束的情况下,尽可能保留更多的视觉token
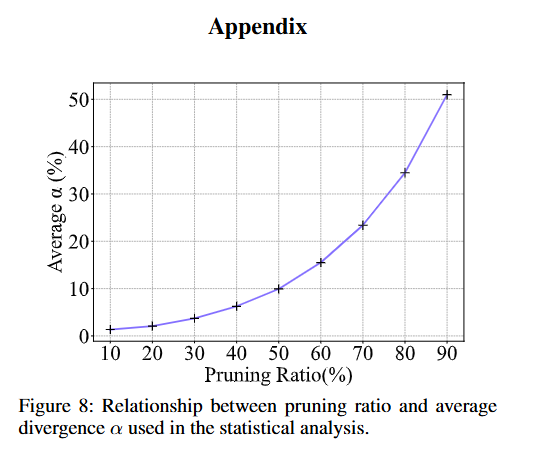
关于这样的算法最后带来的关系,作者附了这么一个曲线
根据策略在推理时修剪
在实际推理时,作者将得到的删除策略应用到模型中。具体来说,对于每一层的视觉token,按照中给定的删除数量进行修剪。
具体删除哪些token呢?作者的方法是,
对于第i层
计算第i层剩余视觉token j的自注意力和和交叉注意力和,然后将这两个和的乘积作为用于排序的参考,排序之后去除最小的个token(是删除数量)
实验结果
作者使用 LLaVA-655k 数据集(Liu et al. 2023b)中的 655 个样本(0.1%)来生成剪枝策略
在LLaVA, LLaVA-HR,LLaVA-NEXT三个具有不同大小的视觉token(7B模型,576,1024,2880 tokens)的模型上进行测试,十余个下游任务数据集上进行测试
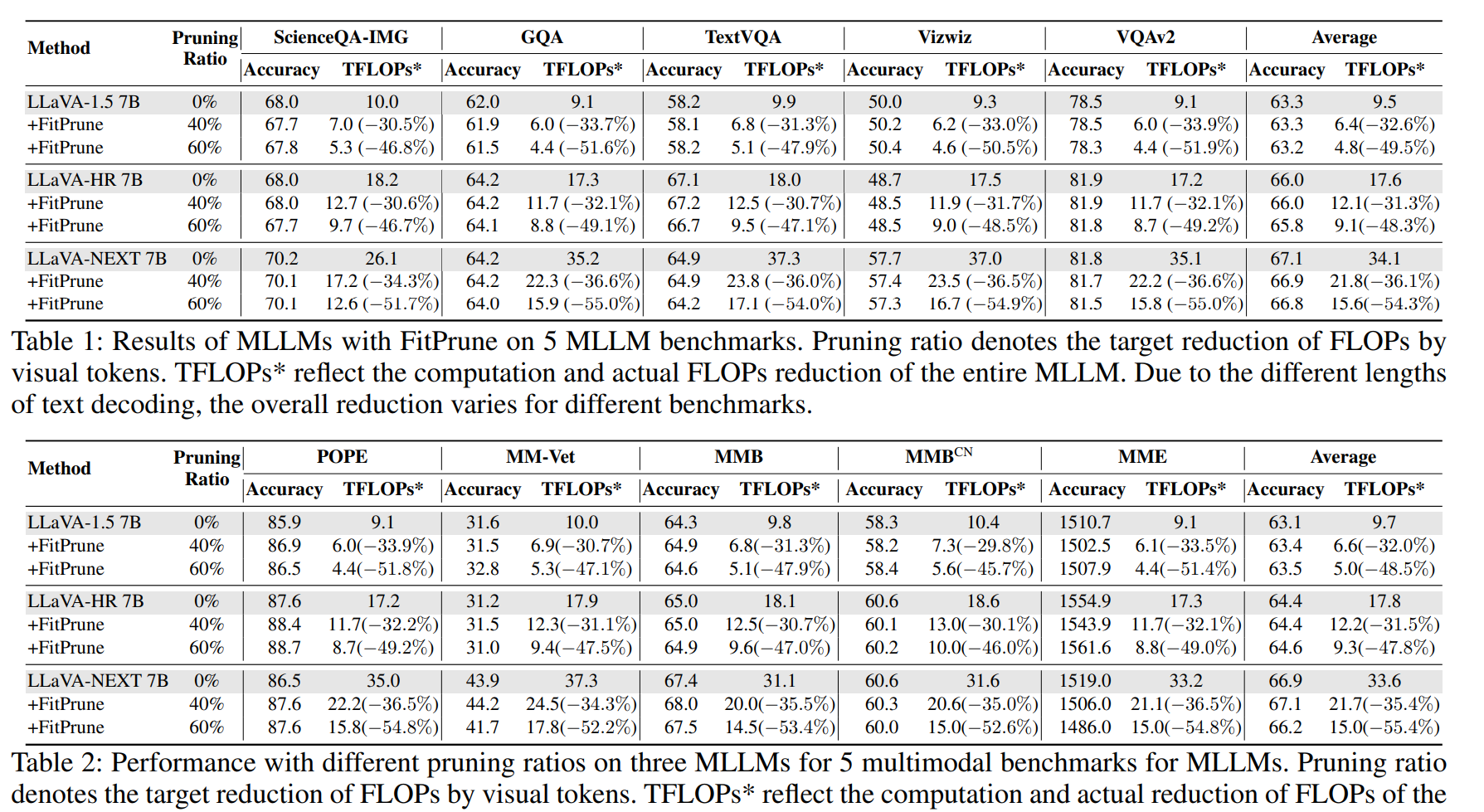
可以看到,剪枝之后,在保持准确率几乎不下降的情况下, 能够带来计算量的大幅下降
作者还做了其他几组实验
-
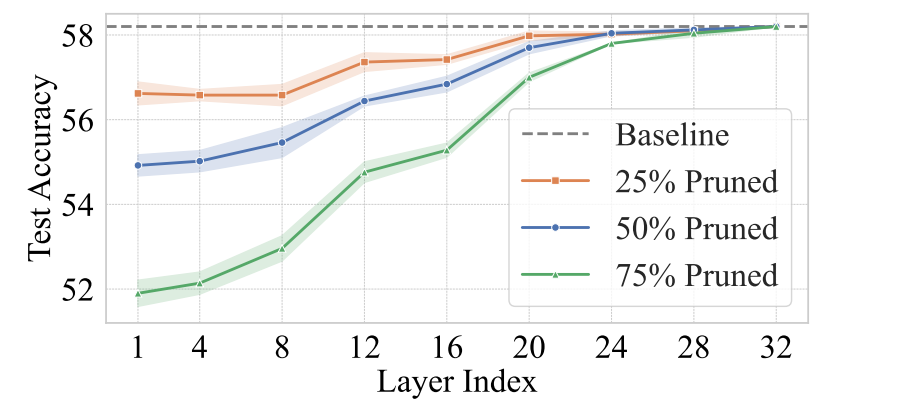
视觉冗余在不同层级的变化
采用在不同层级上,随机删除裁剪视觉Token的方法。作者发现,深层次token的冗余度更高,裁剪深层次token几乎不影响准确度,可视化图也表明深层次的注意力几乎集中在最关键的元素中。但具体到每一层的最佳剪枝比例,层间也有比较大的不同

-
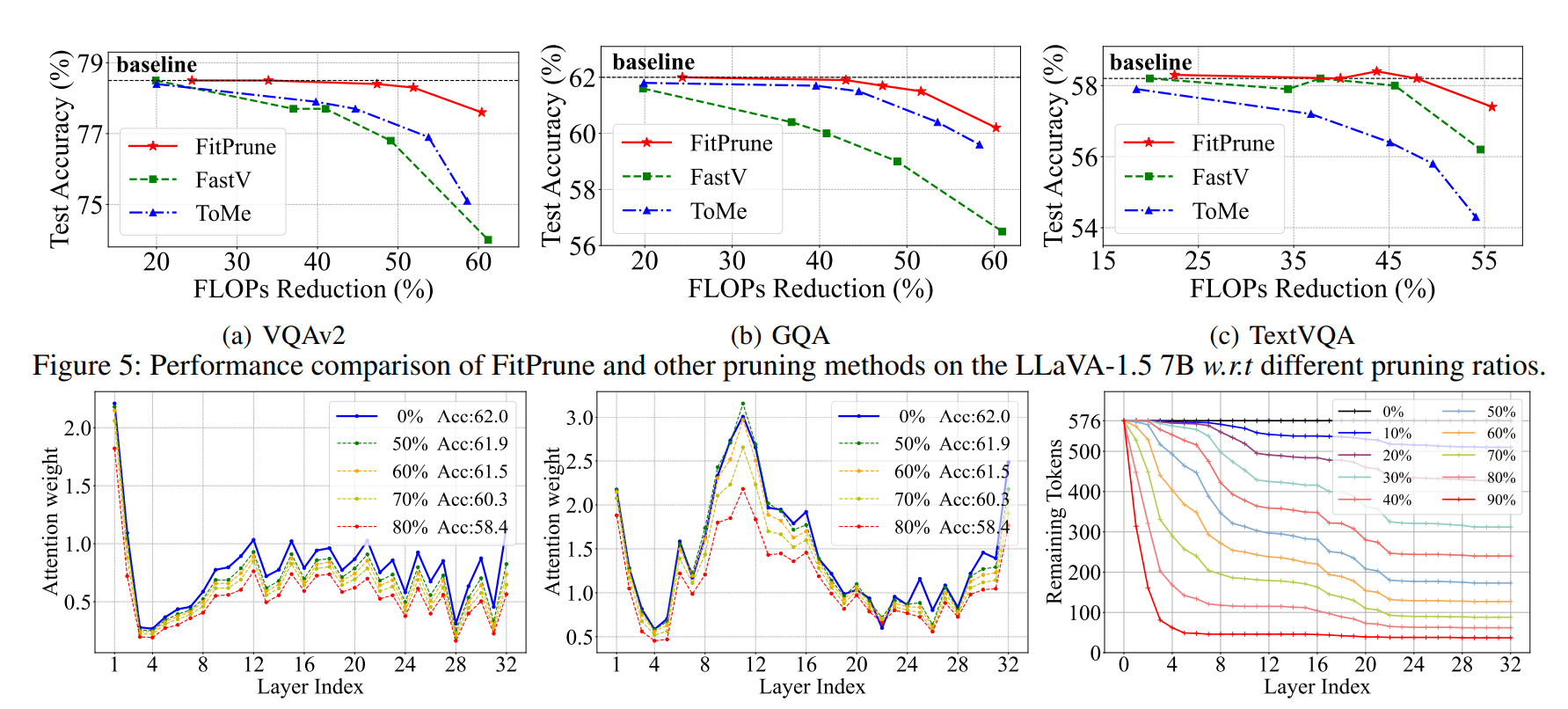
与baseline的对比
对比了FastV和ToMe两种裁剪方法,表明了自身的SOTA性质。同时指出,在裁剪程度低的时候大家都差不多,裁剪程度高的时候才显露方法的性能差距
-
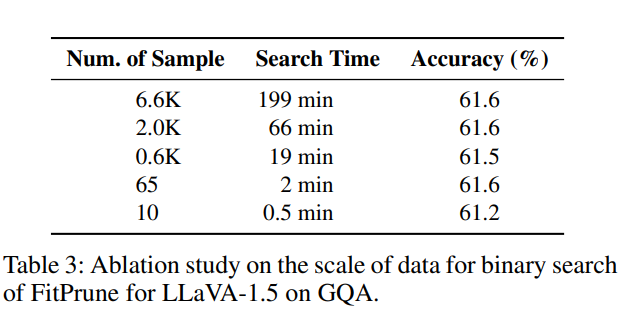
样本数量的消融实验
作者将"LLaVA-655k 数据集(Liu et al. 2023b)中的 655 个样本(0.1%)来生成剪枝策略" 换成1%的数据,发现性能相当。作者进一步推测MLLM层间信息交换的模式可能更多地依赖于模型本身的特性,而在不同的输入样本上有较高的泛化性,FitPrune 方法可以有效地捕捉这种模式。同时下面的表还表明,这个方法有着很强的少样本泛化性,确实是模型的特性而不是样本数据集的特性,在仅有10个样本的时候也能得到非常优秀的策略
结论
作者介绍了一种FitPrune的无训练方法,用于对 MLLMs 进行视觉标记剪枝。通过将标记剪枝问题表述为一个统计问题,FitPrune 旨在最小化注意力分布的偏差,从而实现冗余视觉token的高效剪枝,进而提高计算效率。FitPrune 能够基于少量数据生成最优的剪枝策略,避免了昂贵的手动试验。